后 Hadoop 時代,大數(shù)據(jù)分析路在何方 數(shù)據(jù)處理與存儲服務(wù)的新趨勢
隨著云計(jì)算、人工智能和物聯(lián)網(wǎng)技術(shù)的快速發(fā)展,大數(shù)據(jù)領(lǐng)域進(jìn)入了后 Hadoop 時代。Hadoop 曾經(jīng)是大數(shù)據(jù)處理的基石,但其復(fù)雜性和擴(kuò)展性限制逐漸暴露,推動了新一代數(shù)據(jù)處理和存儲服務(wù)的興起。在這一背景下,大數(shù)據(jù)分析正朝著更高效、更智能的方向演進(jìn)。
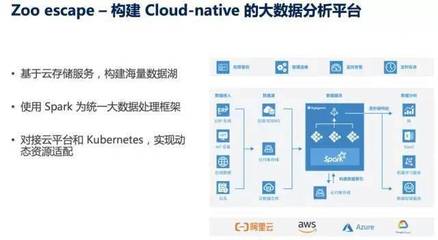
數(shù)據(jù)處理服務(wù)正從批處理向?qū)崟r流處理轉(zhuǎn)變。Apache Spark、Flink 等框架取代了傳統(tǒng)的 MapReduce,支持低延遲的數(shù)據(jù)處理,滿足企業(yè)對實(shí)時洞察的需求。同時,云原生數(shù)據(jù)處理服務(wù),如 AWS Glue 和 Google Dataflow,提供了無服務(wù)器架構(gòu),降低了運(yùn)維成本,提升了可擴(kuò)展性。這些服務(wù)整合了機(jī)器學(xué)習(xí)和 AI 能力,使數(shù)據(jù)分析能夠自動識別模式并預(yù)測趨勢。
存儲服務(wù)也經(jīng)歷了重大革新。對象存儲(如 Amazon S3 和 Google Cloud Storage)成為主流,因其高可用性和低成本特性,適合存儲海量非結(jié)構(gòu)化數(shù)據(jù)。數(shù)據(jù)湖和數(shù)據(jù)倉庫的融合趨勢明顯,例如 Delta Lake 和 Snowflake,支持 ACID 事務(wù)和統(tǒng)一查詢,消除了數(shù)據(jù)孤島問題。云服務(wù)商還推出了多模數(shù)據(jù)庫,如 Cosmos DB,能夠同時處理文檔、圖和時序數(shù)據(jù),適應(yīng)多樣化的業(yè)務(wù)場景。
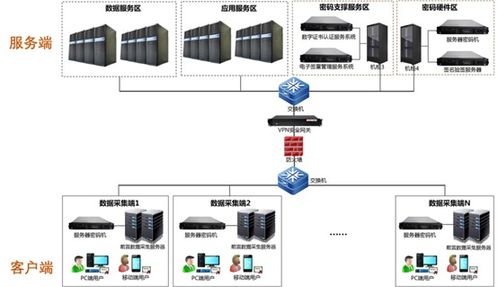
在技術(shù)驅(qū)動之外,數(shù)據(jù)治理和安全成為關(guān)鍵考量。后 Hadoop 時代強(qiáng)調(diào)數(shù)據(jù)隱私和合規(guī)性,服務(wù)集成了加密、訪問控制和審計(jì)功能,確保數(shù)據(jù)在流動中的安全。未來,大數(shù)據(jù)分析將更依賴自動化和智能化,減少人工干預(yù),提升決策效率。
后 Hadoop 時代的大數(shù)據(jù)分析正朝著云原生、實(shí)時化和智能化的方向發(fā)展。企業(yè)和開發(fā)者應(yīng)擁抱這些變革,優(yōu)化數(shù)據(jù)處理和存儲策略,以在數(shù)據(jù)驅(qū)動的世界中保持競爭力。
如若轉(zhuǎn)載,請注明出處:http://www.ppddyy3.com/product/5.html
更新時間:2026-05-20 22:34:35